


Moving Into the Data Center: Servers
Merry Christmas! Hoping to take some time and understand the data center infrastructure stack and IT hardware to build off a knowledge of semiconductors

Up to this point, we’ve primarily written about semiconductors. We’ve established the foundation of the upside down pyramid that defines the tech stack, of which a crude image can be found below.
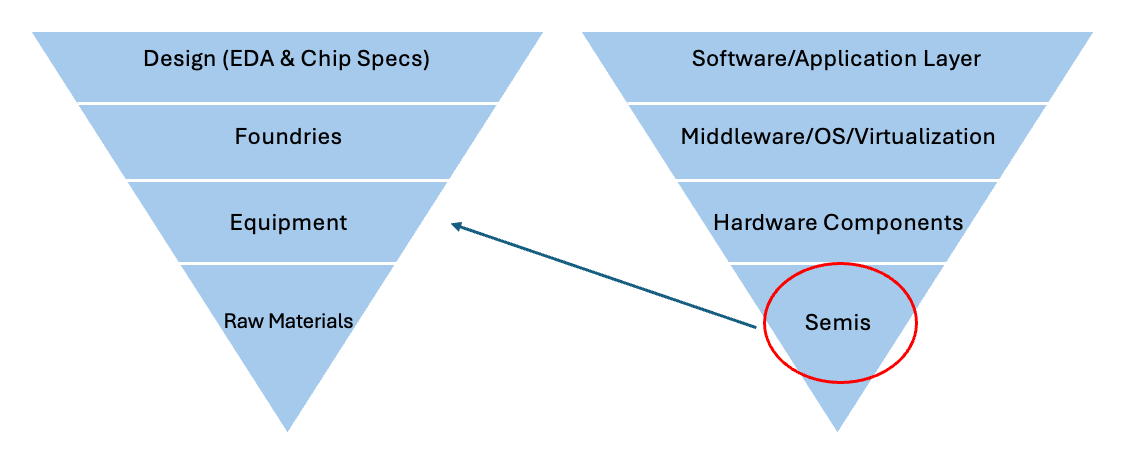
We’ve understood the foundry business (through the context of Intel’s sputtering manufacturing business), the EDA business, and the pricing struggles of the design business as key products commoditize themselves. There’s many ways in which we could dive deeper, and countless subjects to double click on within semis. That said, my goal with this Substack was to get an entry into all the areas of the tech stack. Having spent a semester knee deep in semis, we’re going to keep it moving onto hardware.
What is hardware? The term hardware refers to both the internal and external devices that enable the logic functions of the chip to execute functions. We will primarily be looking at internal devices, which consist of the components we will discuss below, among others. External hardware can break down into input and output components. Input components consist of flash drives, mouses, keyboards, and any other technology that can be used to render instructions to the software. Output components like monitors and speakers render results from the execution of instructions given to the computer.
Within hardware, we can focus on the PC space and the data center infrastructure space. I’ll let you be the arbiter of which one feels more important at this juncture in time, but the scale of both these sub-sectors in the context of the businesses we’ll focus on is such that investors will focus on both. Take Dell, for example, whose Infrastructure Solutions Group (ISG) and Client Solutions Group (CSG) revenue mix has changed drastically since the investment boom into generative AI.
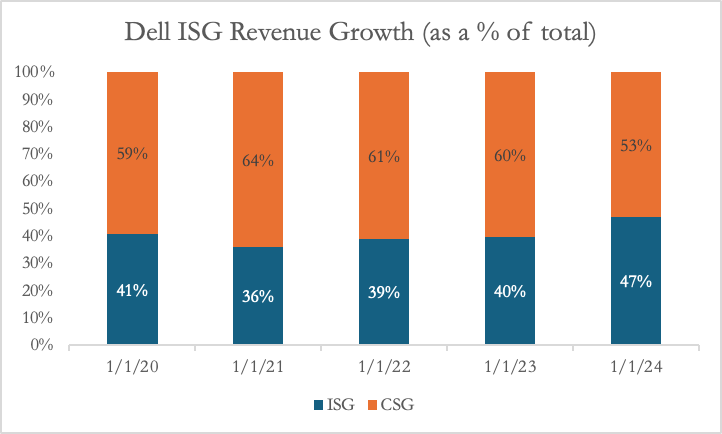
In the context of this article, I want to focus on servers, so we’ll naturally lean towards the data center infra stack. Why servers? Servers are the primary revenue-generating components in the stack and the core computing units of a data center. They directly address end-market needs like AI, cloud computing, and enterprise applications, which are key drivers of data center demand. Further, understanding servers will help us frame future discussions around power, cooling, and networking as supporting functions.
What differentiates a server from a consumer PC? If a consumer computer is a pickup truck, then a server is a semi-truck. You operate both of them in a similar way: steering wheel, pedals, fuel. You can use them to accomplish the same/similar tasks: hauling various loads. But a semi-truck is driven a little bit differently; it has more gears; it can haul more; it is more resilient and can go longer without stopping. In some ways, it is built to be easier to maintain. But underneath all of the nuance, it has the same basic form and function as any consumer device.
Components of a Server
CPU: the brain of the server, performs logical operations. Today, Intel’s x86 64-bit is the primary CPU architecture used in processors.
Memory (RAM): temporary storage for data being actively used by CPU. General purpose servers for file storage and web hosting will typically require anywhere from 2GB to 128GB, while high-performance computing and AI/ML workloads necessitate at least as much RAM as the GPU memory in a system.
Storage (HDD/SSD): dedicated space for data to be stored for long-term access
Hard disk drive (HDD): “non volatile” storage device, meaning it can retail stored data even when no power is supplied to the device. most affordable storage type with most efficient cost per GB, and are now shipping commercially with 20TB of data.
Solid state drives (SSD): uses flash memory (USB) with no moving parts to store data. SSD is also much faster (>5,000MB/s) and have greater durability. However, this also makes them more expensive on a per GB/TB basis
SSDs have fewer power consumption requirements than HDDs because they have no moving components. SSDs also rely on the constant power from the operating device to function. While unpowered SSDs lose data when they are not powered, most SSDs come with a built-in battery, which allows the device to idle and maintain data integrity.

Motherboard: main circuit board in a computer system, connecting all the components. Uses chipsets to manage the flow of data and ensures no two components try to use the same data bus at the same time. Also distributes power to all the connected components
Analogy: can be thought of as a transportation hub in a city (Grand Central) that connects the CPU, RAM, storage, GPU, NIC and other components
Power Supply Unit (PSU): acts as a universal adapter, converting alternating current power (from the grid) into direct current power, required by most server components. server components operate at different voltages (12V for GPUs, 5V for CPU, etc.) so there needs to be a regulator of voltage that can then distribute the power needed
alternating current: type of electrical current in which the direction of the flow of electrons switches back and forth at regular intervals or cycles
direct current: one-directional flow of electric charge

Network interface card (NIC): hardware component (typically a chip) installed on a computer to allow it to connect to a network.
Process: NIC recieves data packet between server and network (LAN, ethernet). It then translates digital signals from the server into network compatible formats
NICs have a unique MAC address used to identify the server across the broader network, which is used to ensure data is sent to the correct device
GPU: accelerates compute-heavy tasks like AI or graphical rendering. parallel processing units optimized for executing many calculations simultaneously
Typically, in AI model training, the CPU will organize and preprocess data into batches while the GPU will process the data faster than the CPU could
If this was part of a larger distributed training setup, the NIC would also coordinate with other servers to share GPU workloads, which is what happens in data centers that operate as “orchestrated GPUs”
Cooling system: recommended temperature for data centers is between 70 and 75 degrees, data center cooling ensures the optimal operating environment for the equipment in the data center
Many different cooling technologies to get into, which we’ll do later
Debates in the Server Space
Debate 1: Within Liquid Cooling, Direct-to-Chip or Immersion?
Okay, to answer this question, we’ll have to get some of the basics about cooling out of the way, so here goes.
Air cooling: AC, fans, vents to circulate air that expels hot air produced by computing equipment. This is the most traditional method of data center cooling, because it is the most easily adaptable to large and small scale facilities. When racks consumed only up to 20kW, this was fine, but with racks exceeding 30kW, air cooling tends to use more energy, driving up costs, hence why larger data centers with ample capital have begun to couple use of air cooling with…
Liquid cooling! Basically take a dielectric fluid that effectively transfers heat from server components without causing any sort of electrical damage. It’s new to data centers, but liquid coolant is in widespread use across the automotive industry, which employs a similar dielectric fluid. At the enterprise level, though, two main categories of liquid cooling have come about
Direct-to-chip (DTC) cooling: A cold plate is placed directly on the chips, and the electric components are never in direct contact with the coolant. Pipes essentially bring the liquid straight to the GPU or CPU, and the liquid absorbs the heat before flowing out to be cooled and reused
One Phase cooling: Cooling liquid remains in the same state throughout the process, flowing back as a warm liquid to a cooling system. Think of a car radiator - simpler design, but not as efficient with very high amounts of heat
Two phase: In two phase, the cooling liquid changes state when absorbing heat. It evaporates into a gas, then is cooled using a condenser to repeat the cycle. This is better for extreme heat loads, like intensive model training

Immersion cooling: cools the servers by submerging them entirely into a dielectric fluid
Single phase: servers are submerged, and the cooling liquid absorbs the heat from the components and gets warmer before being pumped into a heat exchanger where it is cooled down before circulating back
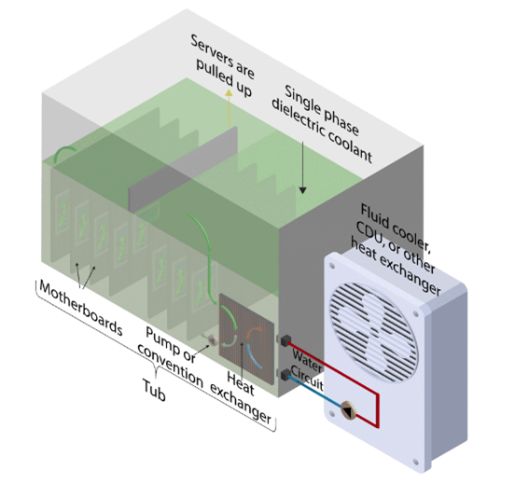
Source: Data Center Dynamics
Two phase: servers are submerged, liquid boils when touching the hot components, causing the gas to rise. The gas then hits a cooling plate, which turns it back into liquid to then drip back into the tank to start again
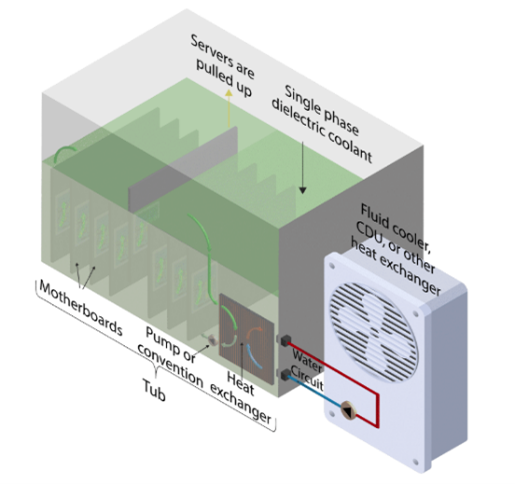

So what is the debate around these two? From a thermal resistance perspective, you’ll notice in the diagrams that, while DTC cooling exists only to serve the chip (hence the name), immersion cooling addresses the whole system, cooling other components like the hard disk that would otherwise require another cooling solution. As a result, immersion cooling provides more energy savings (50% when compared to air cooling), albeit at a higher price. We’ve talked about how thermal considerations are coming to the fore in memory, a trend which I believe will continue. So data centers conscious about cooling not just the chip but the other components of a rack will prefer immersion cooling depending on their price elasticity.
On the cost front, existing data centers with air cooling infrastructure will have an easier time integrating DTC cooling, as the additional immersion tanks and coolant circulation won’t be required. In this regard, one’s choice of DTC vs. immersion depends on whether they are aiming to repurpose an existing data center for HPC or building a new one altogether.
Debate #2: The Blackwell Ramp’s Margin Floor/Ceiling
Going into 3Q, there were a lot of concerns surrounding Blackwell. Chief among them was the liquid leakage issues in liquid cooled AI servers, although cooling vendor and ODMs have largely tested and solved these issues through, thus why the industry has relatively high confidence that the production cycle won’t see any snags. The questions going into the quarter that still remain is on the margin front. From Semi Analysis’ article on Blackwell’s TCO…
In the last generation, with the H100, the performance/TCO uplift over the A100 was poor due to the huge increase in pricing, with the A100 actually having better TCO than the H100 in inference because of the H100’s anemic memory bandwidth gains and massive price increase from the A100’s trough pricing in Q3 of 2022. This didn’t matter much though because the massive requirements in the AI industry for training as opposed to inference benefited more from H100’s greater FLOPS performance, and most the price increase was driven by opportunistically high margins from Nvidia.
The Blackwell upgrade has a very different pricing approach out of necessity. Whereas H100 was really the only game in town, hyperscalers are starting to introduce their own silicon in the game, while AMD’s MI300X has begun to close the price-performance gap.
Consider both graphs below, courtesy of RunPod blog’s comparison between the AMD MI300X and Nvidia’s H100. We can see that for smaller batch sizes, the H100 SXM and MI300X have similar throughput, but the MI300X has significantly lower costs per 1M tokens. As we get into medium to large batch sizes, MI300X loses its throughput advantage but retains a slight cost advantage. To be clear, Nvidia is still the gold standard because 1) Blackwell is the best product for the most price insensitive buyers of servers (hyperscalers) and 2) the surrounding software of CUDA is a moat in and of itself.

That being said, the competition outlined above has necessitated competitive pricing that may change the margin profile of the company. During the third quarter earnings call, Nvidia CFO Colette Kress answered a question on this topic by ensuring investors of their goal that the April quarter (when Nvidia expects Blackwell to surpass Hopper in production) will be the gross margin bottom before stabilizing in the mid-70s beyond then. Given the threat of internal silicon from Nvidia’s buyers remains, the surety of Kress’ claim definitely leaves a debate to be had.
What implications does this have across the server stack?
Firstly, lower relative cost increases has the potential to drive increased deployments, which will become a volume driver across the stack and even into co-located data centers outside of just the hyperscalers.
At the OEM level, the lower cost of Blackwell may enable OEMs to bundle GPUs into server offerings at a more attractive price point, which will result in more GPU-heavy server configurations, driving higher ASP. A lower cost would also likely drive a server refresh cycle among enterprises, driving volume growth among the OEMs. Of course, hyperscalers may also leverage Nvidia’s competitive pricing position to negotiate on their own, but I believe the custom integration opportunity and firmware optimization will leave the server OEM in an advantageous spot.
Within cooling, the competitive pricing of Blackwell relative to MI300X and internally developed chips may lead to lower cost sensitivity on cooling, for example, in light of lower TCO across the server stack. This could accelerate a shift into immersion cooling which, as we’ve discussed, allows for greater energy efficiency despite higher up-front investment.
Appendix #1: Walking Through The Blackwell Server Production Process
Chip fabrication: TSMC manufactures the Blackwell GPU at it’s 4nm node, and cuts the wafer into individual die
Packaging: To integrate memory and other chip components, TSMC packages the connected die using its chip on wafer on substrate (CoWoS-L) process flow, which mounts the die onto a silicon substrate allowing for electrical connectivity. This process also allows for the integration of HBM
Module assembly: Puts the packaged GPU onto a printed circuit board (PCB), on which we can add power regulators and other supporting components to optimize functionality. Blackwell specifically mobilizes a 10TB/s interconnect (NV-Link) to connect dies for better performance. This can be done with Ariel (one Grace CPU, one Blackwell GPU) or Bianca (one Grace CPU, two Blackwell GPUs). (source)
Systems integration: Once the GPU boards have been assembled, original design manufacturers (ODMs) like Foxconn and Quanta will build the servers to be shipped to the hyperscalers, integrating the components from above.
Original equipment manufacturers: The difference between an OEM and ODM is simple. ODMs like the systems integrators described above will build servers provided they have client-given specifications (in this case, Nvidia’s). OEMs, on the other hand, add further value through software integration (OpenManage from Dell) and support services.
Both OEMs and ODMs can ship product to clients