


The Investment Implications of Scaling Law Saturation

Today I want to spend a bit of time talking about the investment implications of scaling laws saturating, which has been talked about more due to lagging LLM timelines and performance. I’ll first explain what scaling laws are, and why they’re important in the context of AI investment as they exist today. I will then frame the backdrop under which the question is being posed, pointing to multiple signs that traditional scaling laws may not provide an accurate roadmap for future investment. Finally, I will walk through what I see as the implications of this theme, bringing in some historical context from the dot-com era that may or may not apply
What are scaling laws currently?
According to Epoch AI, “the term ‘scaling laws’ in deep learning refers to relations between functional properties of interest (usually the test loss or some performance metric for fine-tuning tasks) and properties of the architecture or optimization process (like model size, width, or training compute).” The “law,” in these cases, dictates that increasing certain factors will increase the quality of a model in asymptotic fashion. These factors include but are not limited to…
Model size (parameter count): More parameters enable the model to capture more complex patterns and relationships
Data size (amount of training data): Using larger datasets generally leads to better performance, as the model learns from a more diverse and extensive range of examples
Compute power (FLOP count): Research shows that increasing computational resources leads to an increase in the performance of a model
Below is a series of plots from a seminal paper from OpenAI in 2020 explaining the power-law relationship that minimizes the loss function. We can see from each of these that increasing all three of the factors above, over time, leads to a consistent optimization of the test loss.

It’s important to acknowledge the scaling limits here. The power-law relationship shown suggests a practical limit as the loss function approaches a certain point (which researchers would like to be 0). Thus, the benefits of increasing a model’s dataset size, for example, from 1 billion to 2 billion tokens, are likely to be far greater than increasing from 10 billion to 20 billion tokens, especially when the costs and resource requirements of 10 billion parameters are what they are.
Think of this analogy: a student reading their first ten books is likely to learn much more within those ten books than the next ten. And the ten after that will teach them even less due to diminishing marginal returns.
At present, these scaling laws dictate much of the hyperscaler thinking surrounding the development of LLMs, hence the near-gluttonous amounts of capital expenditures being undertaken by the hyperscalers over the past few years. The more compute they can have (power is the largest constraint without Dennard scaling, which we spoke about in the memory article), the more data they can train on, the better model they’ll have and the earlier one company will be able to establish a lead.
 : r/NVDA_Stock")
Signals of Scaling Laws Reaching a Saturation Point
It’s important to state that multiple foundational model CEOs have acknowledged the mischaracterization of the term “scaling laws.” In an interview with Lex Fridman on Monday, Anthropic CEO Dario Amodei acknowledged “People call them scaling laws. That’s a misnomer. Like Moore’s law is a misnomer. Moore’s laws, scaling laws, they’re not laws of the universe. They’re empirical regularities. I am going to bet in favor of them continuing, but I’m not certain of that.”
That said, there have been an increasing number of cracks in the armor to the empirical regularities Amodei is referring to. Not so much that the laws themselves are wrong but that we are reaching the natural barriers at which the laws can be beneficial for us because of resource limitations.
Orion (GPT’s upcoming model) is a good example. According to Bloomberg,
“Orion did not hit OpenAI’s desired performance, according to two people familiar with the matter, who spoke on condition of anonymity to discuss company matters. As of late summer, for example, Orion fell short when trying to answer coding questions that it hadn’t been trained on, the people said.”
Anthropic, meanwhile, has had to consistently push back the timetable for Opus 3.5, the latest model set to come out under Claude.
Much of this is a data issue. Youtube videos and WSJ archive have gotten us to where we are today, but now we are running out of data that can incrementally increase the performance of these models. In June of 2024, Epoch AI updated a paper titled “Will we run out of data? Limits of LLM scaling based on human-generated data.” In it, the authors discuss the current trajectory of LLM development, showing that, if trends continue, the available supply of public text data will be exhausted between 2026 and 2032.
LLMs will require massive amounts of diverse data to improve, a depletion which could hinder further scaling. To address this, the paper examines potential alternatives like synthetic data generation, transfer learning, and improvements in data efficiency to support ongoing model progress even in a data-scarce future.
The issue here then becomes the quality, not the quantity, of data. Synthetic data often fails to capture the complexity of real-world data, which can negatively impact inferential model. I’d refer to this IBM study that argues synthetic data may not effectively anticipate a wide range of use cases and individual scenarios. To mitigate this, companies like OpenAI have been partnering with publishers such as Conde Nast and Vox Media
Additionally, as we’ve discussed, the growth of these models require more memory and bandwidth to process data efficiently, which brings us to bandwidth limits on moving data quickly enough to support the increasing parameter size of models.

To be clear, I am not making the claim that the scaling laws are changing or breaking in any way. Nor am I saying that we are at the ceiling of compute efficiency. I’m simply pointing to evidence that the law of diminishing returns exists in this space. Further, the nature of achieving scale may change without the consistent presence of enough high quality data and capable bandwidth to generate incremental model improvements. With this in mind, I want to explore the investment implications of this happening, because it’s something we will have to confront at some point regardless.
Implication 1: Infrastructure as an Enabler, Not a Value Driver. Focus on the Application Layer
The recent is from Andrew Homan of Maverick Capital on last week’s episode of Invest Like the Best.
So when I think about the broader AI ecosystem, we think about it as a three-layer cake, right? So the bottom layer—chips and cloud—that's where we're focused. The middle layer would be the foundational models, and then the top layer would be the applications built on top of those. So the foundational models would be OpenAI, Anthropic, Gemini, etc.
That chip cloud layer would be Nvidia, AMD, TSMC, etc. And then that top layer would be ChatGPT, Office, Copilot, Tesla Full Self-Driving. And I think the challenge right now is that on those top two layers, it's very foggy in terms of who the ultimate winners are going to be and how much value is going to accrue to those layers.
Broadly, eventually, yeah, there will be big dollars that go (to the application layer). But in terms of who actually captures, though, I think it's very opaque right now.
In the words of Mark Twain, “history doesn’t repeat itself, but it often rhymes.” I don’t disagree that the winners and losers in the top two layers are opaque right now, and at the end of the day, investors hate uncertainty. But given this is purely conjectural, let’s assume he’s wrong. Let’s assume that the lack of high quality data is a structural issue within the industry and will create a natural barrier to the scaling laws that have brought us where we are today.
This would consolidate the tech value stack sooner than expected, and a handful of foundational model companies serving as utilities for the broader ecosystem (more on that later). For investors, this scenario provides the necessary clarity; the race to dominate AI shifts from being one of infinite scale to one of resource allocation, efficiency, and execution, wherein I believe unique business ideas like the ones we’ll discuss below will thrive.
In the internet age, we had a similar point in time where investment themes were centered around the picks and shovels needed for the internet. After all, it was the only sure thing amid a thousand IPOs a day that were claiming to be tech companies.
Cisco quick case: At the time, this benefited Cisco more than any other company. As the leading producer of networking hardware, Cisco’s sales (and stock price) went parabolic during the dot-com bubble, infatuating investors with the idea that they were the company holding to key to all the unlocked value that would lie within the internet age. In many ways they were right - Cisco’s routers and switches formed the backbones of the internet and, similar to Nvidia, they had the numbers to back up their exorbitant valuation for a period in time.
Eventually that would burst along with the rest of the dot-com bubble. Part of this also happened because connectivity limits were reached; with already fast and reliable connectivity, adding hardware didn’t yield the same incremental returns in the same way that adding compute or data will not add the same incremental return for future models of GPT as it did for 3.5 and 4.

From Financial Times Over time, this led to the realization that physical infrastructure alone wasn’t enough to drive value in the internet economy. While a robust network backbone was crucial, the real value laid in applications that could make use of the infrastructure.

Bringing it to today, Microsoft CTO said on an interview in July
“If you’re starting a company right now, and you believe that you have to build your very own frontier model in order to go deliver an application to someone, that’s almost the same thing as saying, like, I gotta go build my own smartphone, hardware and operating system in order to deliver this mobile app. Like, maybe you need it, but like, probably you don’t.”
The takeaway here (for me) is that the real winners in AI won’t need to build their own foundational models or infrastructure. Rather, they will leverage existing models and infrastructure to create applications. Further, the saturation of scaling laws and the diminishing returns of more compute, similar to the diminishing returns of faster internet connectivity, will serve as an accelerant of this trend. Thus, I would expect greater value accrual within the AI application stack, particularly as it relates to agentic AI.
Implication 1b: Inference over Training Takes us to the Edge
In the scenario outlined above, training becomes cost-prohibitive, as it will become less economically incentivized given the massive costs and relatively lackluster model improvements. At this point in time, the pretrained models that cost billions to develop will dominate the market, and will serve as reusable assets on top of which the application layer can be built, as noted by Homan in the earlier quote.
Unsurprisingly, this will serve as an accelerant from what is now training focus (embodied through a gold rush for Nvidia’s GPUs) to an inference focus wherein efficient deployment of the capitally intensive models become the name of the game. And that brings us to edge AI, which refers to localized inference models on devices.
Edge computing: moves the compute power physically closer to where the data is generated, usually some sort of sensor. Uses stream processing, as the computer is taking in data and constantly deciding what to do with it, rather than the batch processing of cloud
Importantly, edge AI reduces the need for large amounts of data to travel through servers - referred to as lower latency. when you hear latency, think of inefficiencies due to data traveling
Key differences between cloud and edge computing
Location: cloud containers are stored at the data center level, while edge containers (devices) are located at the edge of the network, closer to the data source to optimize on latency
Edge AI is an integral next step because this is where all the real world application is. Think about everything we’re being sold on with AI: predictive maintenance in factories, AR/VR devices, autonomous cars, AI agents. In this scenario, you don’t need the huge AGI that can do everything; you need a GPT that’s smarter and smaller that can reduce unit economics to a point where it can be deployed. So then it becomes about taking these large foundational models and downsizing them to domain-specific applications which, in many ways, could replicate and even exceed the benefits of the software era that followed the cloud infrastructure boom of the early 2010s.
So what’s the investment takeaway? There are two buckets/themes I believe would benefit here.
I personally really like model optimization tools, which are necessary for making large AI models smaller and more energy efficient for deployment at the edge. For businesses, this drastically reduces the total cost of ownership (TCO), while optimization can be evaluated financially in a simliar way to SaaS businesses given the high revenue predictability. Put simply, model optimization companies will thrive by removing bottlenecks in deploying large foundational models on constrained edge devices, creating cost efficiences. This does assume a level of bullishness on enterprise AI spend, but this has been confirmed by multiple surveys recently. From CIO dive...
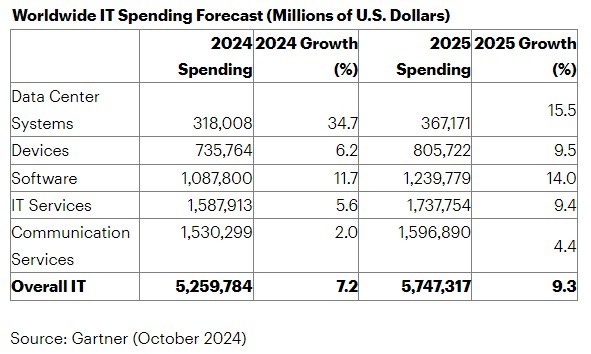
As the hyperscaler building boom snowballed, Dell’Oro Group said it expected infrastructure spend to surpass $400 billion this year, a bit above the $318 billion Gartner forecasted Wednesday. The segment is expected to add another $50 billion in 2025, as enterprises add AI processing capacity, according to Gartner.
I also think Apple is set for a massive winning streak once inferential applications begin to pick up. As create-your-own poop emojis start to translate into predictive typing, they benefit more than anyone from the end-user consumer adoption. Having the chips and software integrated vertically will also serve as a gross margin incremental tailwind. More than anything, however, I think edge AI device integration will reinforce the pricing power that Apple’s elongated upgrading cycle suggests they may be losing.
Implication 2: Foundational Model Companies Form A New Bedrock
One might think that reaching the natural limitations of these scaling laws would be bad for foundation model companies because their models aren’t improving. And yes, it does stand to reason that they will increase costs (short-term) to ensure they are reaching the natural limitations before cutting back on spend because that’s all anyone can do in an arms race. And yes, Sam Altman and Dario Amodei want their GPTs to rival Nobel Laureates in terms of knowledge. But if this is not feasible due to data limitations, or even bandwidth limitations, then it’s just not feasible. Regardless of why or how it happens, this would finally allow the OpenAIs and Anthropics of the world to finally reduce their cash burn, which has been ballistic. The following is from Dylan Patel and Azfal Ahmad of Semis Analysis.
We built a cost model indicating that ChatGPT costs $694,444 per day to operate in compute hardware costs. OpenAI requires ~3,617 HGX A100 servers (28,936 GPUs) to serve Chat GPT. We estimate the cost per query to be 0.36 cents.
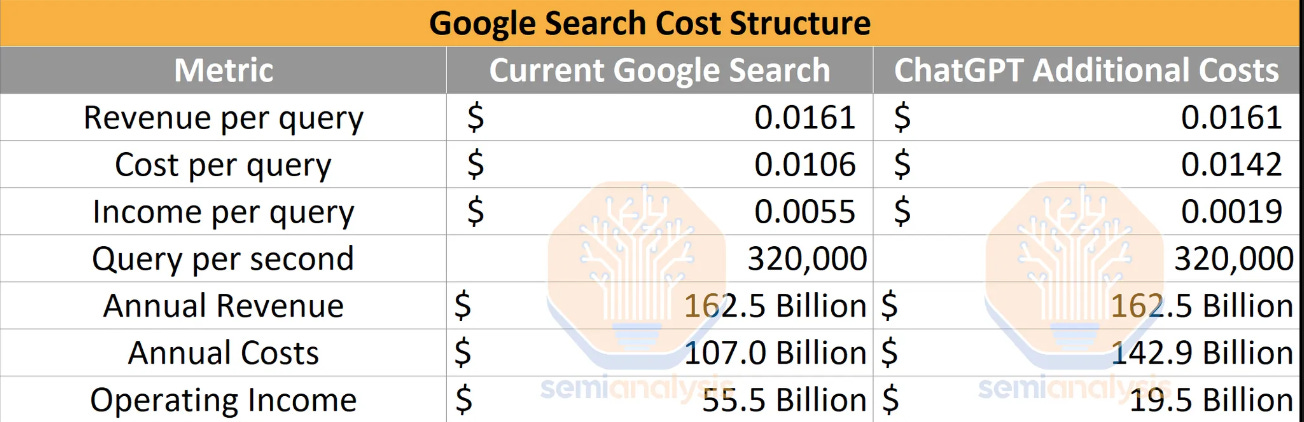
High computing costs, along with the amortization of research compute and increasing employee salaries for scarce AI engineering talent, are expected to drive a loss of $5 billion this year, according to the Information. The publication suggests that those losses could reach $14b in 2026 as the cost of obtaining high quality data and running compute continues to increase.

So we can see why it might be in the interests of foundation models to begin seeing some saturation so the focus can shift to deployment instead of training.
In the cloud era, AWS, Azure and GCP have been digesting the profits of its early, capitally intensive, cloud infrastructure investment and will continue to do so. In a similar vein, these early foundation model companies will finally be able to digest profits and see cash flow positivity from these scaling laws reaching a barrier. Going back to Homan’s three layer cake adage, I believe foundation models, previously the middle layer, will turn into the bottom layer upon which applications are built while the chip and cloud companies will rather be in support of optimizing the usage of those models.
This is why the cash burn has to be so high right now. So long as the scaling laws are still in play, the top three or four players are fighting to reach the barrier. However, that barrier will incite an inflection point that will allow them to deploy models at scale through lucrative licensing deals, along with domain specific APIs and fine tuning.
In Conclusion…
There is no guarantee that the scaling laws are reaching a saturation point. As Amodei put eloquently in the Fridman interview,
At every stage of scaling, there are always arguments. And when I first heard them honestly, I thought, “Probably I’m the one who’s wrong and all these experts in the field are right. They know the situation better than I do, right?” There’s the Chomsky argument about, “You can get syntactics but you can’t get semantics.” There was this idea, “Oh, you can make a sentence make sense, but you can’t make a paragraph make sense.” The latest one we have today is, “We’re going to run out of data, or the data isn’t high quality enough or models can’t reason.” And each time, every time, we manage to either find a way around or scaling just is the way around. Sometimes it’s one, sometimes it’s the other. And so I’m now at this point, I still think it’s always quite uncertain. We have nothing but inductive inference to tell us that the next two years are going to be like the last 10 years. But I’ve seen the movie enough times, I’ve seen the story happen for enough times to really believe that probably the scaling is going to continue
So we really don’t know how all this will play out, except for the fact that capex will likely inflect further upwards before inflecting downwards as companies ensure their search for these natural limitations is complete. At that point, and at that point only, can the application layer start creating the benefits to society we’ve been promised, and I’m excited for the investment ideas that will emerge as a result.
I would caution against the idea that scaling limits will be a solely bad thing for AI companies. It may mean that the expected evolution of the technology will not be as society transforming as it may have seemed at face value, but it will create an infrastructure digestion period that allows for earlier monetization.
P.S. It’s probably the best for AI safety if scaling laws start to slow down in the interest of letting regulation catch up. See this article from a friend of mine, Sunny Gandhi, on the lagging speed of AI regulation.